The author selected the Computer History Museum to receive a donation as part of the Write for DOnations program.
Introduction
Zabbix is open-source monitoring software for networks and applications. It offers real-time monitoring of thousands of metrics collected from servers, virtual machines, network devices, and web applications. These metrics can help you determine the current health of your IT infrastructure and detect problems with hardware or software components before customers complain. Useful information is stored in a database so you can analyze data over time and improve the quality of provided services or plan upgrades of your equipment.
Zabbix uses several options for collecting metrics, including agentless monitoring of user services and client-server architecture. To collect server metrics, it uses a small agent on the monitored client to gather data and send it to the Zabbix server. Zabbix supports encrypted communication between the server and connected clients, so your data is protected while it travels over insecure networks.
The Zabbix server stores its data in a relational database powered by MySQL or PostgreSQL. You can also store historical data in NoSQL databases like Elasticsearch and TimescaleDB. Zabbix provides a web interface so you can view data and configure system settings.
In this tutorial, you will configure Zabbix on two Ubuntu 20.04 machines. One will be configured as the Zabbix server, and the other as a client that you’ll monitor. The Zabbix server will use a MySQL database to record monitoring data and use Nginx to serve the web interface.
Prerequisites
To follow this tutorial, you will need:
- Two Ubuntu 20.04 servers set up by following the Initial Server Setup Guide for Ubuntu 20.04, including a non-root user with sudo privileges and a firewall configured with
ufw. On one server, you will install Zabbix; this tutorial will refer to this as the Zabbix server. It will monitor your second server; this second server will be referred to as the second Ubuntu server.
- The server that will run the Zabbix server needs Nginx, MySQL, and PHP installed. Follow Steps 1–3 of our Ubuntu 20.04 LEMP Stack guide to configure those on your Zabbix server.
- A registered domain name. This tutorial will use
your_domain throughout. You can purchase a domain name from Namecheap, get one for free with Freenom, or use the domain registrar of your choice.
- Both of the following DNS records set up for your Zabbix server. If you are using DigitalOcean, please see our DNS documentation for details on how to add them.
- An A record with
your_domain pointing to your Zabbix server’s public IP address.
- An A record with
www.your_domain pointing to your Zabbix server’s public IP address.
Additionally, because the Zabbix Server is used to access valuable information about your infrastructure that you would not want unauthorized users to access, it’s important that you keep your server secure by installing a TLS/SSL certificate. This is optional but strongly encouraged. If you would like to secure your server, follow the Let’s Encrypt on Ubuntu 20.04 guide after Step 3 of this tutorial.
Step 1 — Installing the Zabbix Server
First, you need to install Zabbix on the server where you installed MySQL, Nginx, and PHP. Log in to this machine as your non-root user:
- ssh sammy@zabbix_server_ip_address
Zabbix is available in Ubuntu’s package manager, but it’s outdated, so use the official Zabbix repository to install the latest stable version. Download and install the repository configuration package:
- wget https://repo.zabbix.com/zabbix/5.0/ubuntu/pool/main/z/zabbix-release/zabbix-release_5.0-1+focal_all.deb
- sudo dpkg -i zabbix-release_5.0-1+focal_all.deb
You will see the following output:
Output
Selecting previously unselected package zabbix-release.
(Reading database ... 64058 files and directories currently installed.)
Preparing to unpack zabbix-release_5.0-1+focal_all.deb ...
Unpacking zabbix-release (1:5.0-1+focal) ...
Setting up zabbix-release (1:5.0-1+focal) ...
Update the package index so the new repository is included:
Then install the Zabbix server and web frontend with MySQL database support:
- sudo apt install zabbix-server-mysql zabbix-frontend-php
Also, install the Zabbix agent, which will let you collect data about the Zabbix server status itself.
- sudo apt install zabbix-agent
Before you can use Zabbix, you have to set up a database to hold the data that the Zabbix server will collect from its agents. You can do this in the next step.
Step 2 — Configuring the MySQL Database for Zabbix
You need to create a new MySQL database and populate it with some basic information in order to make it suitable for Zabbix. You’ll also create a specific user for this database so Zabbix isn’t logging in to MySQL with the root account.
Log in to MySQL as the root user:
Create the Zabbix database with UTF-8 character support:
- create database zabbix character set utf8 collate utf8_bin;
Then create a user that the Zabbix server will use, give it access to the new database, and set the password for the user:
- create user zabbix@localhost identified by ‘your_zabbix_mysql_password‘;
- grant all privileges on zabbix.* to zabbix@localhost;
That takes care of the user and the database. Exit out of the database console.
Next you have to import the initial schema and data. The Zabbix installation provided you with a file that sets this up.
Run the following command to set up the schema and import the data into the zabbix database. Use zcat since the data in the file is compressed:
- zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -p zabbix
Enter the password for the zabbix MySQL user that you configured when prompted.
This command may take a minute or two to execute. If you see the error ERROR 1045 (28000): Access denied for userzabbix@'localhost' (using password: YES) then make sure you used the right password for the zabbix user.
In order for the Zabbix server to use this database, you need to set the database password in the Zabbix server configuration file. Open the configuration file in your preferred text editor. This tutorial will use nano:
- sudo nano /etc/zabbix/zabbix_server.conf
Look for the following section of the file:
/etc/zabbix/zabbix_server.conf
...
### Option: DBPassword
# Database password. Ignored for SQLite.
# Comment this line if no password is used.
#
# Mandatory: no
# Default:
# DBPassword=
...
These comments in the file explain how to connect to the database. You need to set the DBPassword value in the file to the password for your database user. Add this line after those comments to configure the database:
/etc/zabbix/zabbix_server.conf
...
DBPassword=your_zabbix_mysql_password
...
Save and close zabbix_server.conf by pressing CTRL+X, followed by Y and then ENTER if you’re using nano.
You’ve now configured the Zabbix server to connect to the database. Next, you will configure the Nginx web server to serve the Zabbix frontend.
Step 3 — Configuring Nginx for Zabbix
To configure Nginx automatically, install the automatic configuration package:
- sudo apt install zabbix-nginx-conf
As a result, you will get the configuration file /etc/zabbix/nginx.conf, as well as a link to it in the Nginx configuration directory /etc/nginx/conf.d/zabbix.conf.
Next, you need to make changes to this file. Open the configuration file:
- sudo nano /etc/zabbix/nginx.conf
The file contains an automatically generated Nginx server block configuration. It contains two lines that determine the server name and what port it is listening on:
/etc/zabbix/nginx.conf
server {
# listen 80;
# server_name example.com;
...
Uncomment the two lines, and replace example.com with your domain name. Your settings will look like this:
/etc/zabbix/nginx.conf
server {
listen 80;
server_name your_domain;
...
Save and close the file. Next, test to make sure that there are no syntax errors in any of your Nginx files and reload the configuration:
- sudo nginx -t
- sudo nginx -s reload
Now that Nginx is set up to serve the Zabbix frontend, you will make some modifications to your PHP setup in order for the Zabbix web interface to work properly.
Note: As mentioned in the Prerequisites section, it is recommended that you enable SSL/TLS on your server. If you would like to do this, follow our Ubuntu 20.04 Let’s Encrypt tutorial before you move on to Step 4 to obtain a free SSL certificate for Nginx. This process will automatically detect your Zabbix server block and configure it for HTTPS. After obtaining your SSL/TLS certificates, you can come back and complete this tutorial.
Step 4 — Configuring PHP for Zabbix
The Zabbix web interface is written in PHP and requires some special PHP server settings. The Zabbix installation process created a PHP-FPM configuration file that contains these settings. It is located in the directory /etc/zabbix and is loaded automatically by PHP-FPM. You need to make a small change to this file, so open it up with the following:
- sudo nano /etc/zabbix/php-fpm.conf
The file contains PHP settings that meet the necessary requirements for the Zabbix web interface. However, the timezone setting is commented out by default. To make sure that Zabbix uses the correct time, you need to set the appropriate timezone:
/etc/zabbix/php-fpm.conf
...
php_value[max_execution_time] = 300
php_value[memory_limit] = 128M
php_value[post_max_size] = 16M
php_value[upload_max_filesize] = 2M
php_value[max_input_time] = 300
php_value[max_input_vars] = 10000
; php_value[date.timezone] = Europe/Riga
Uncomment the timezone line highlighted in the preceding code block and change it to your timezone. You can use this list of supported time zones to find the right one for you. Then save and close the file.
Now restart PHP-FPM to apply these new settings:
- sudo systemctl restart php7.4-fpm.service
You can now start the Zabbix server:
- sudo systemctl start zabbix-server
Then check whether the Zabbix server is running properly:
- sudo systemctl status zabbix-server
You will see the following status:
Output
● zabbix-server.service - Zabbix Server
Loaded: loaded (/lib/systemd/system/zabbix-server.service; disabled; vendor preset: enabled)
Active: active (running) since Fri 2020-06-12 05:59:32 UTC; 36s ago
Process: 27026 ExecStart=/usr/sbin/zabbix_server -c $CONFFILE (code=exited, status=0/SUCCESS)
...
Finally, enable the server to start at boot time:
- sudo systemctl enable zabbix-server
The server is set up and connected to the database. Next, set up the web frontend.
Step 5 — Configuring Settings for the Zabbix Web Interface
The web interface lets you see reports and add hosts that you want to monitor, but it needs some initial setup before you can use it. Launch your browser and go to the address http://zabbix_server_name or https://zabbix_server_name if you set up Let’s Encrypt. On the first screen, you will see a welcome message. Click Next step to continue.
On the next screen, you will see the table that lists all of the prerequisites to run Zabbix.
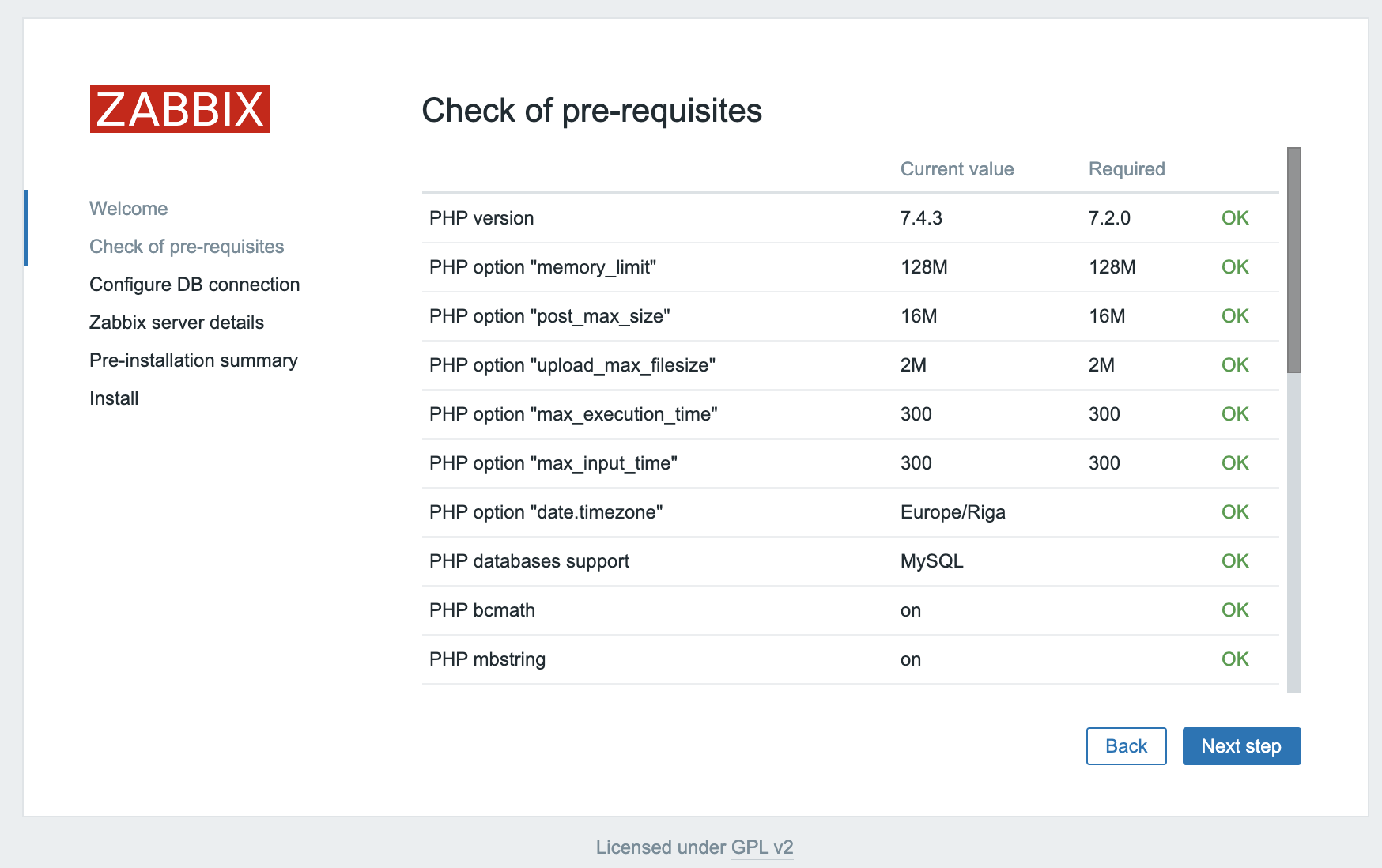
All of the values in this table must be OK, so verify that they are. Be sure to scroll down and look at all of the prerequisites. Once you’ve verified that everything is ready to go, click Next step to proceed.
The next screen asks for database connection information.
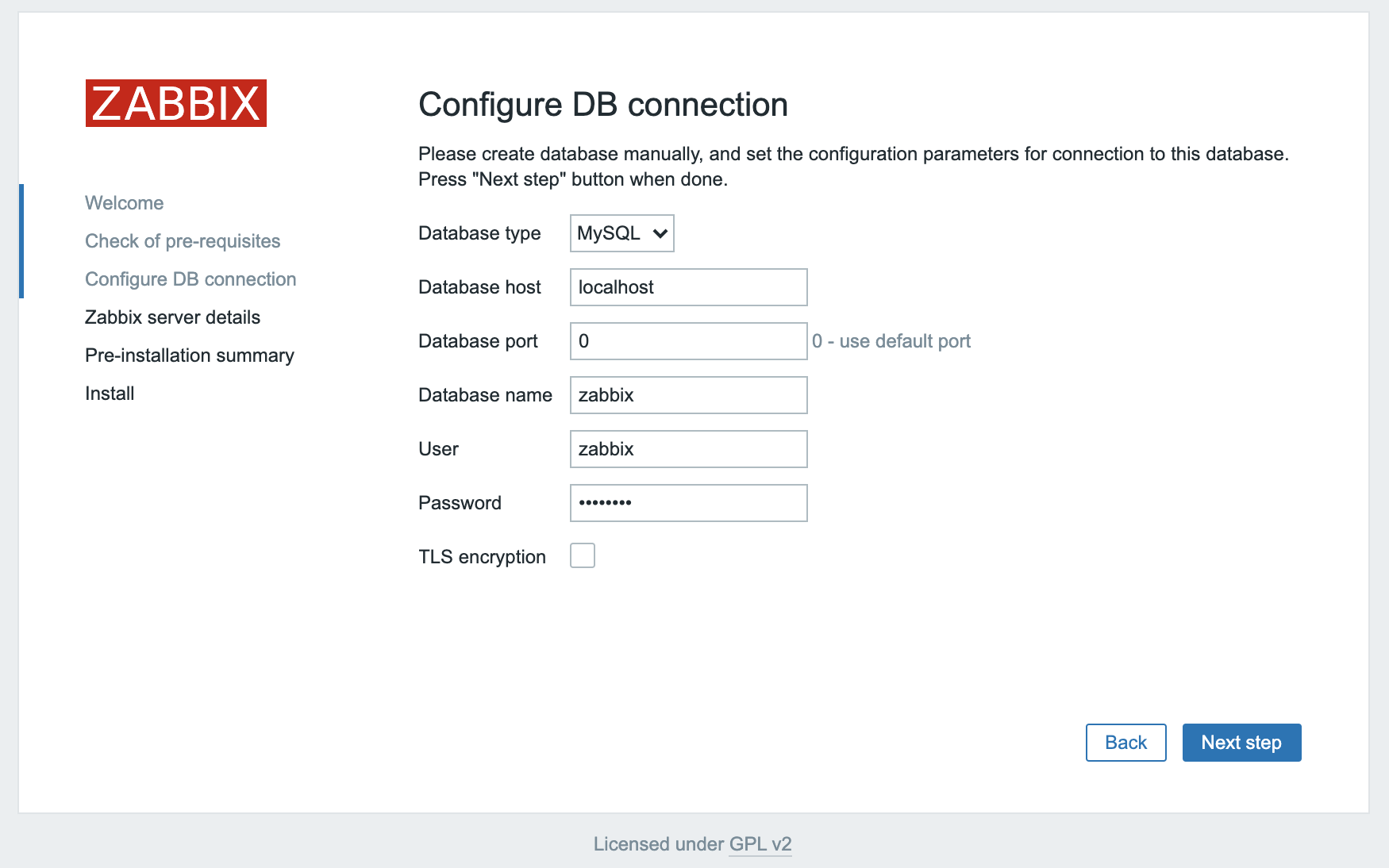
You told the Zabbix server about your database, but the Zabbix web interface also needs access to the database to manage hosts and read data. Therefore enter the MySQL credentials you configured in Step 2. Click Next step to proceed.
On the next screen, you can leave the options at their default values.
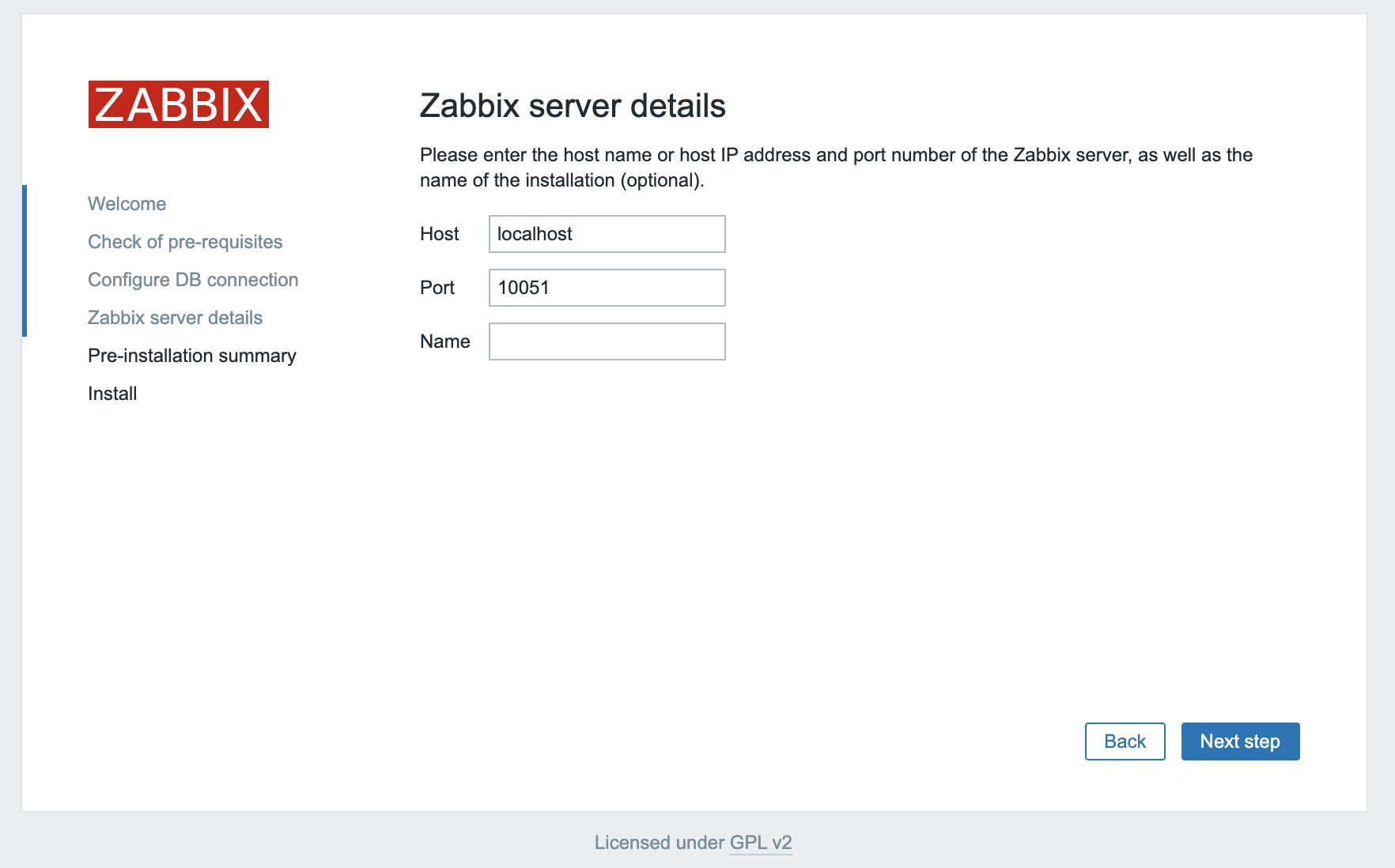
The Name is optional; it is used in the web interface to distinguish one server from another in case you have several monitoring servers. Click Next step to proceed.
The next screen will show the pre-installation summary so you can confirm everything is correct.
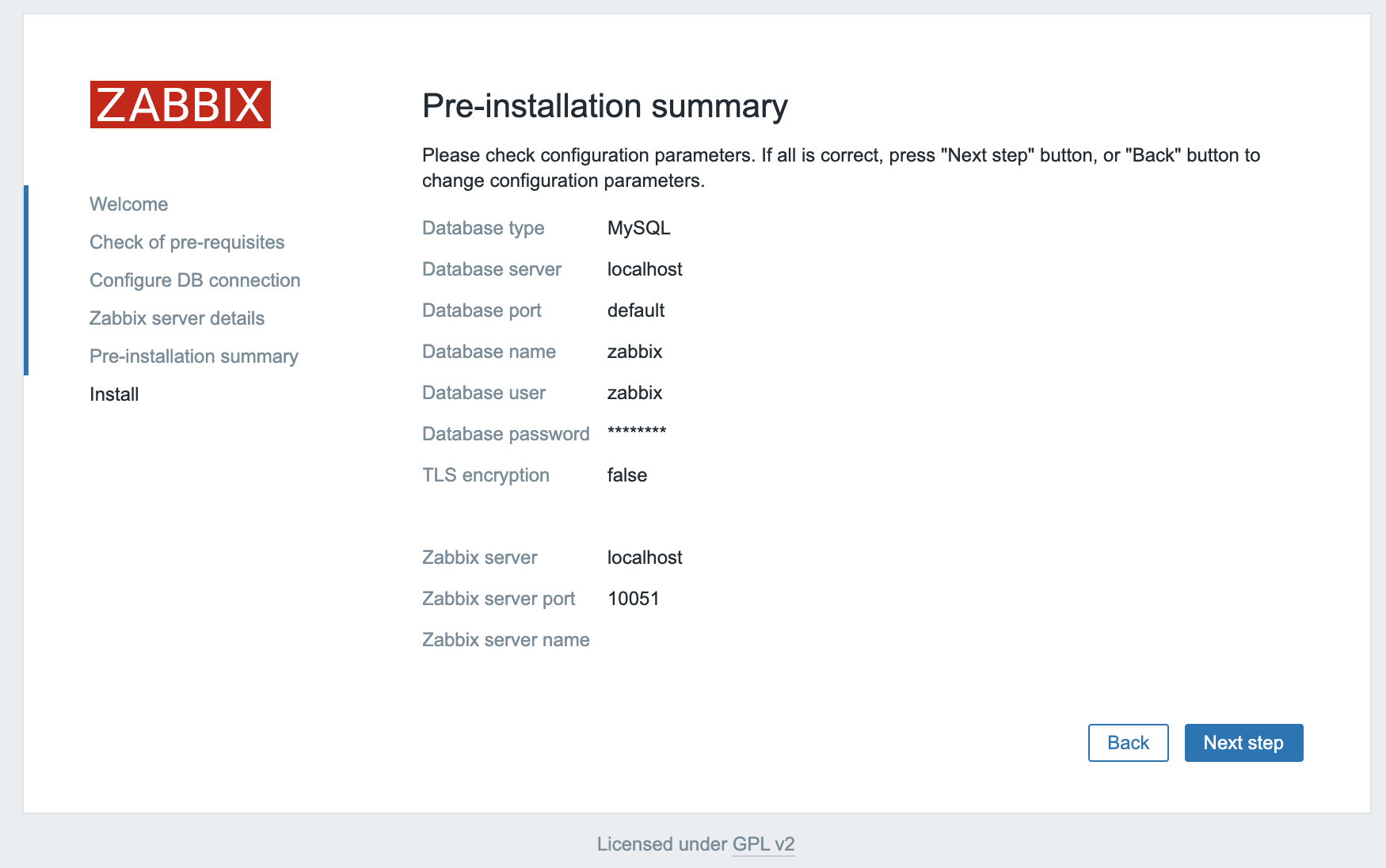
Click Next step to proceed to the final screen.
The web interface setup is now complete. This process creates the configuration file /usr/share/zabbix/conf/zabbix.conf.php, which you could back up and use in the future. Click Finish to proceed to the login screen. The default user is Admin and the password is zabbix.
Before you log in, set up the Zabbix agent on your second Ubuntu server.
Step 6 — Installing and Configuring the Zabbix Agent
Now you need to configure the agent software that will send monitoring data to the Zabbix server.
Log in to the second Ubuntu server:
- ssh sammy@second_ubuntu_server_ip_address
Just like on the Zabbix server, run the following commands to install the repository configuration package:
- wget https://repo.zabbix.com/zabbix/5.0/ubuntu/pool/main/z/zabbix-release/zabbix-release_5.0-1+focal_all.deb
- sudo dpkg -i zabbix-release_5.0-1+focal_all.deb
Next, update the package index:
Then install the Zabbix agent:
- sudo apt install zabbix-agent
While Zabbix supports certificate-based encryption, setting up a certificate authority is beyond the scope of this tutorial. But you can use pre-shared keys (PSK) to secure the connection between the server and agent.
First, generate a PSK:
- sudo sh -c “openssl rand -hex 32 > /etc/zabbix/zabbix_agentd.psk”
Show the key by using cat so you can copy it somewhere:
- cat /etc/zabbix/zabbix_agentd.psk
The key will look something like this:
Output
75ad6cb5e17d244ac8c00c96a1b074d0550b8e7b15d0ab3cde60cd79af280fca
Save this for later; you will need it to configure the host.
Now edit the Zabbix agent settings to set up its secure connection to the Zabbix server. Open the agent configuration file in your text editor:
- sudo nano /etc/zabbix/zabbix_agentd.conf
Each setting within this file is documented via informative comments throughout the file, but you only need to edit some of them.
First you have to edit the IP address of the Zabbix server. Find the following section:
/etc/zabbix/zabbix_agentd.conf
...
### Option: Server
# List of comma delimited IP addresses, optionally in CIDR notation, or DNS names of Zabbix servers and Zabbix proxies.
# Incoming connections will be accepted only from the hosts listed here.
# If IPv6 support is enabled then '127.0.0.1', '::127.0.0.1', '::ffff:127.0.0.1' are treated equally
# and '::/0' will allow any IPv4 or IPv6 address.
# '0.0.0.0/0' can be used to allow any IPv4 address.
# Example: Server=127.0.0.1,192.168.1.0/24,::1,2001:db8::/32,zabbix.example.com
#
# Mandatory: yes, if StartAgents is not explicitly set to 0
# Default:
# Server=
Server=127.0.0.1
...
Change the default value to the IP of your Zabbix server:
/etc/zabbix/zabbix_agentd.conf
...
Server=zabbix_server_ip_address
...
By default, Zabbix server connects to the agent. But for some checks (for example, monitoring the logs), a reverse connection is required. For correct operation, you need to specify the Zabbix server address and a unique host name.
Find the section that configures the active checks and change the default values:
/etc/zabbix/zabbix_agentd.conf
...
##### Active checks related
### Option: ServerActive
# List of comma delimited IP:port (or DNS name:port) pairs of Zabbix servers and Zabbix proxies for active checks.
# If port is not specified, default port is used.
# IPv6 addresses must be enclosed in square brackets if port for that host is specified.
# If port is not specified, square brackets for IPv6 addresses are optional.
# If this parameter is not specified, active checks are disabled.
# Example: ServerActive=127.0.0.1:20051,zabbix.domain,[::1]:30051,::1,[12fc::1]
#
# Mandatory: no
# Default:
# ServerActive=
ServerActive=zabbix_server_ip_address
### Option: Hostname
# Unique, case sensitive hostname.
# Required for active checks and must match hostname as configured on the server.
# Value is acquired from HostnameItem if undefined.
#
# Mandatory: no
# Default:
# Hostname=
Hostname=Second Ubuntu Server
...
Next, find the section that configures the secure connection to the Zabbix server and enable pre-shared key support. Find the TLSConnect section, which looks like this:
/etc/zabbix/zabbix_agentd.conf
...
### Option: TLSConnect
# How the agent should connect to server or proxy. Used for active checks.
# Only one value can be specified:
# unencrypted - connect without encryption
# psk - connect using TLS and a pre-shared key
# cert - connect using TLS and a certificate
#
# Mandatory: yes, if TLS certificate or PSK parameters are defined (even for 'unencrypted' connection)
# Default:
# TLSConnect=unencrypted
...
Then add this line to configure pre-shared key support:
/etc/zabbix/zabbix_agentd.conf
...
TLSConnect=psk
...
Next, locate the TLSAccept section, which looks like this:
/etc/zabbix/zabbix_agentd.conf
...
### Option: TLSAccept
# What incoming connections to accept.
# Multiple values can be specified, separated by comma:
# unencrypted - accept connections without encryption
# psk - accept connections secured with TLS and a pre-shared key
# cert - accept connections secured with TLS and a certificate
#
# Mandatory: yes, if TLS certificate or PSK parameters are defined (even for 'unencrypted' connection)
# Default:
# TLSAccept=unencrypted
...
Configure incoming connections to support pre-shared keys by adding this line:
/etc/zabbix/zabbix_agentd.conf
...
TLSAccept=psk
...
Next, find the TLSPSKIdentity section, which looks like this:
/etc/zabbix/zabbix_agentd.conf
...
### Option: TLSPSKIdentity
# Unique, case sensitive string used to identify the pre-shared key.
#
# Mandatory: no
# Default:
# TLSPSKIdentity=
...
Choose a unique name to identify your pre-shared key by adding this line:
/etc/zabbix/zabbix_agentd.conf
...
TLSPSKIdentity=PSK 001
...
You’ll use this as the PSK ID when you add your host through the Zabbix web interface.
Then set the option that points to your previously created pre-shared key. Locate the TLSPSKFileoption:
/etc/zabbix/zabbix_agentd.conf
...
### Option: TLSPSKFile
# Full pathname of a file containing the pre-shared key.
#
# Mandatory: no
# Default:
# TLSPSKFile=
...
Add this line to point the Zabbix agent to your PSK file you created:
/etc/zabbix/zabbix_agentd.conf
...
TLSPSKFile=/etc/zabbix/zabbix_agentd.psk
...
Save and close the file. Now you can restart the Zabbix agent and set it to start at boot time:
- sudo systemctl restart zabbix-agent
- sudo systemctl enable zabbix-agent
For good measure, check that the Zabbix agent is running properly:
- sudo systemctl status zabbix-agent
You will see the following status, indicating the agent is running:
Output
● zabbix-agent.service - Zabbix Agent
Loaded: loaded (/lib/systemd/system/zabbix-agent.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2020-06-12 08:19:54 UTC; 25s ago
...
The agent will listen on port 10050 for connections from the server. Configure UFW to allow connections to this port:
You can learn more about UFW in How To Set Up a Firewall with UFW on Ubuntu 20.04.
Your agent is now ready to send data to the Zabbix server. But in order to use it, you have to link to it from the server’s web console. In the next step, you will complete the configuration.
Step 7 — Adding the New Host to the Zabbix Server
Installing an agent on a server you want to monitor is only half of the process. Each host you want to monitor needs to be registered on the Zabbix server, which you can do through the web interface.
Log in to the Zabbix Server web interface by navigating to the address http://zabbix_server_name or https://zabbix_server_name:
When you have logged in, click on Configuration and then Hosts in the left navigation bar. Then click the Create host button in the top right corner of the screen. This will open the host configuration page.
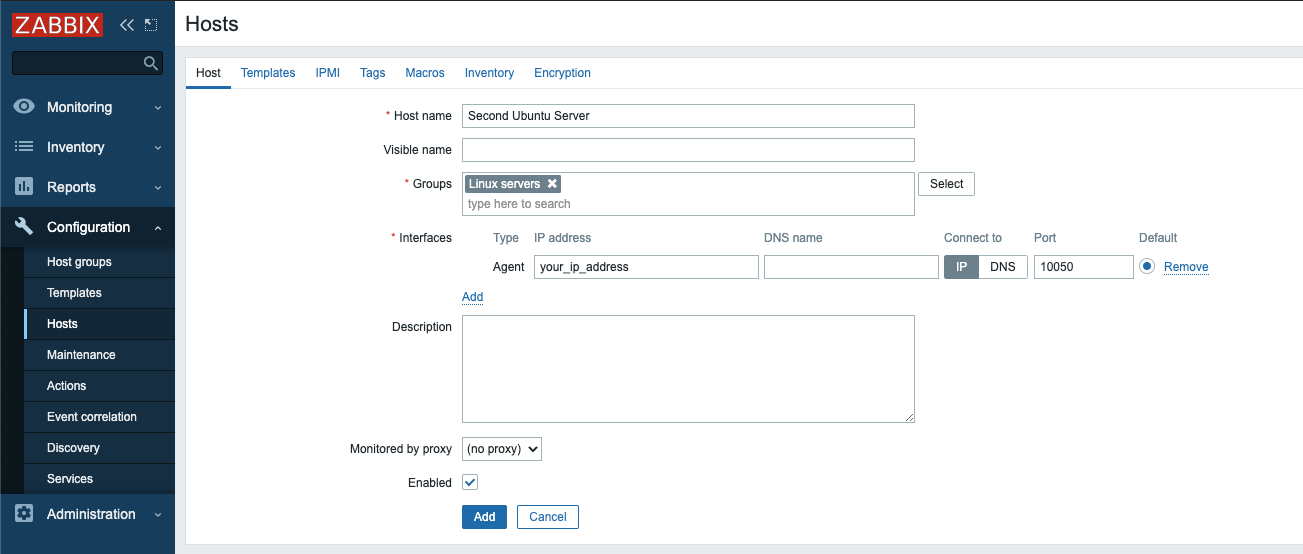
Adjust the Host name and IP address to reflect the host name and IP address of your second Ubuntu server, then add the host to a group. You can select an existing group, for example Linux servers, or create your own group. The host can be in multiple groups. To do this, enter the name of an existing or new group in the Groups field and select the desired value from the proposed list.
Before adding the group, click the Templates tab.
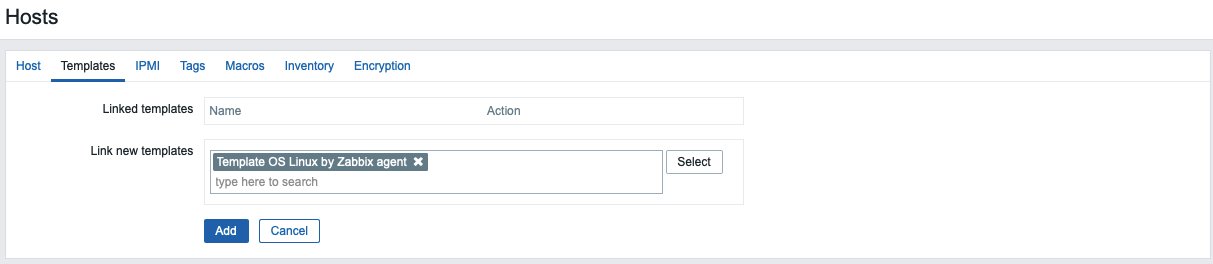
Type Template OS Linux by Zabbix agent in the Search field and then select it from the list to add this template to the host.
Next, navigate to the Encryption tab. Select PSK for both Connections to host and Connections from host. Then set PSK identity to PSK 001, which is the value of the TLSPSKIdentity setting of the Zabbix agent you configured previously. Then set PSK value to the key you generated for the Zabbix agent. It’s the one stored in the file /etc/zabbix/zabbix_agentd.psk on the agent machine.
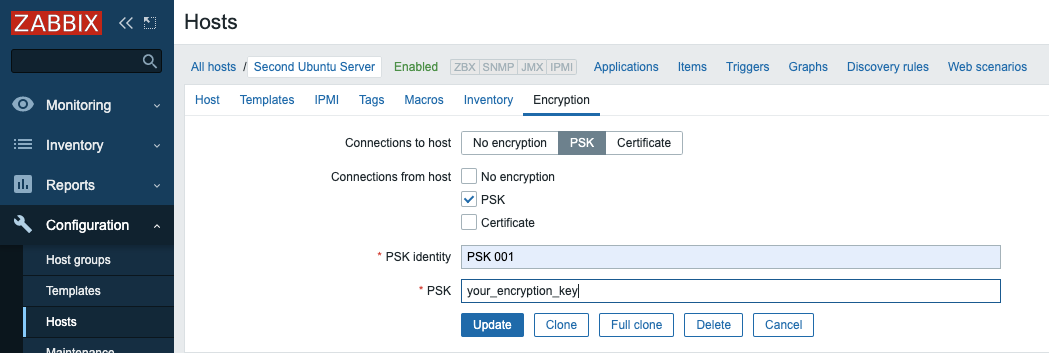
Finally, click the Add button at the bottom of the form to create the host.
You will see your new host in the list. Wait for a minute and reload the page to see green labels indicating that everything is working fine and the connection is encrypted.
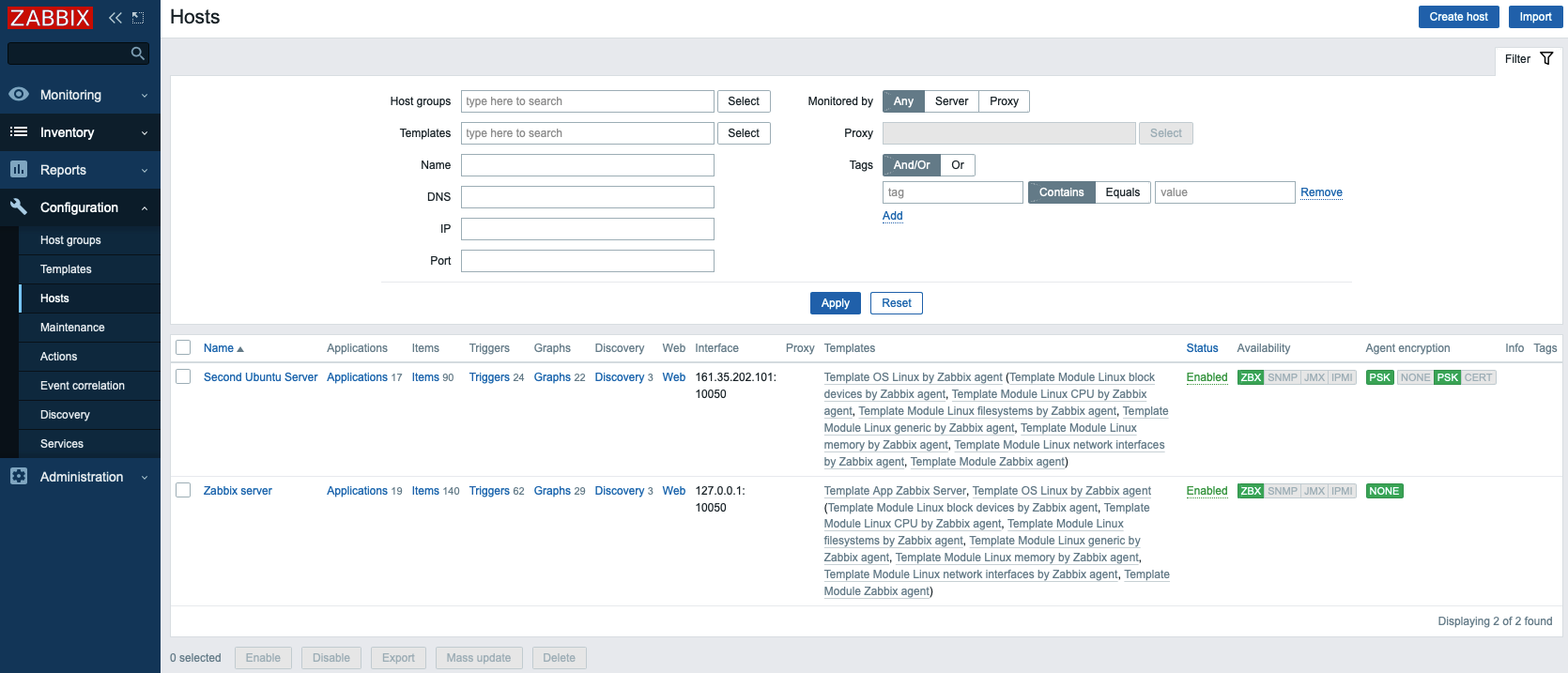
If you have additional servers you need to monitor, log in to each host, install the Zabbix agent, generate a PSK, configure the agent, and add the host to the web interface following the same steps you followed to add your first host.
The Zabbix server is now monitoring your second Ubuntu server. Now, set up email notifications to be notified about problems.
Step 8 — Configuring Email Notifications
Zabbix automatically supports many types of notifications: email, OTRS, Slack, Telegram, SMS, etc. You can see the full list of integrations at the Zabbix website.
As an example, this tutorial will configure notifications for the Email media type.
Click on Administration, and then Media types in the left navigation bar. You will see the list of all media types. There are two preconfigured options for emails: for the plain text notification and for the HTML notifications. In this tutorial you will use plain text notification. Click on Email.
Adjust the SMTP options according to the settings provided by your email service. This tutorial uses Gmail’s SMTP capabilities to set up email notifications; if you would like more information about setting this up, see How To Use Google’s SMTP Server.
Note: If you use 2-Step Verification with Gmail, you need to generate an App Password for Zabbix. You’ll only have to enter an App password once during setup. You will find instructions on how to generate this password in the Google Help Center.
If you are using Gmail, type in smtp.gmail.com for the SMTP server field, 465 for the SMTP server port field, gmail.com for SMTP helo, and your email for SMTP email. Then choose SSL/TLS for Connection security and Username and password for Authentication. Enter your Gmail address as the Username, and the App Password you generated from your Google account as the Password.
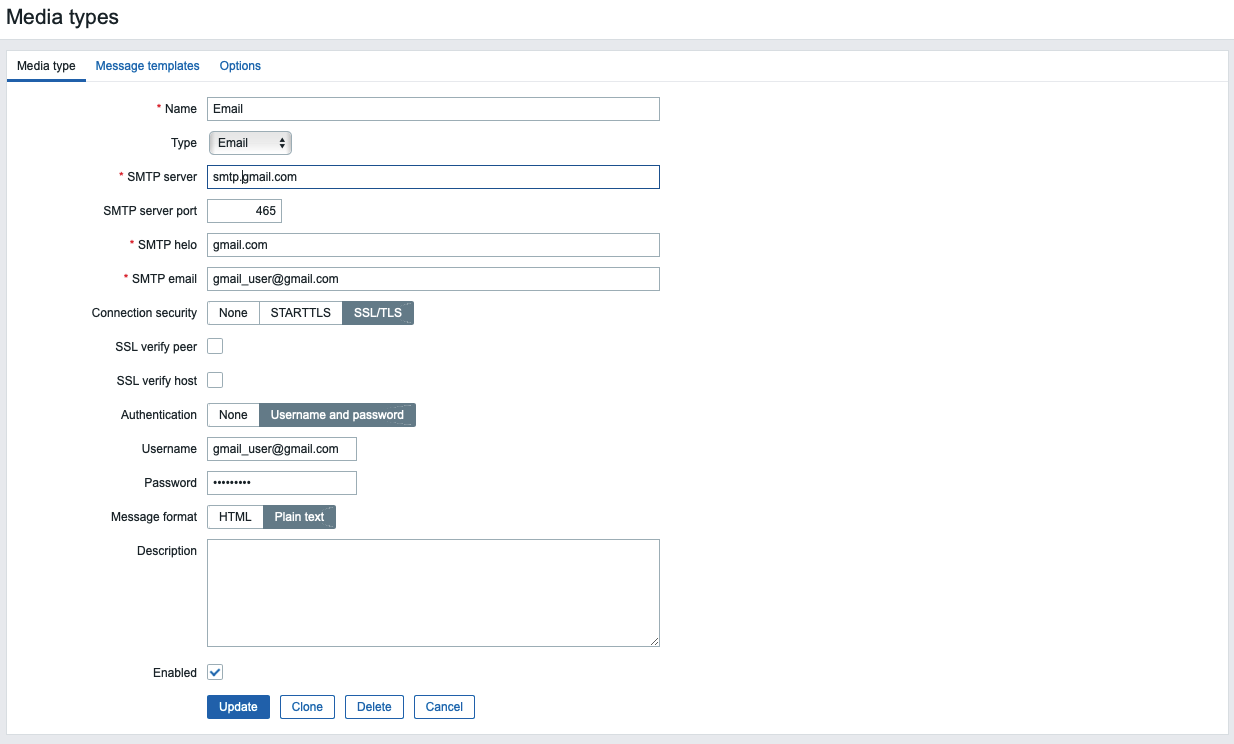
On the Message templates tab you can see the list of predefined messages for various types of notifications. Finally, click the Update button at the bottom of the form to update the email parameters.
Now you can test sending notifications. To do this, click the Test underlined link in the corresponding line.
You will see a pop-up window. Enter your email address in the Send to field and click the Testbutton. You will see a message about the successful sending and you will receive a test message.
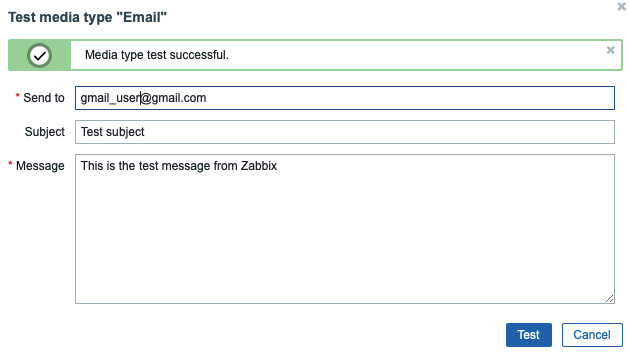
Close the pop-up by clicking the Cancel button.
Now, create a new user. Click on Administration, and then Users in the left navigation bar. You will see the list of users. Then click the Create user button in the top right corner of the screen. This will open the user configuration page:
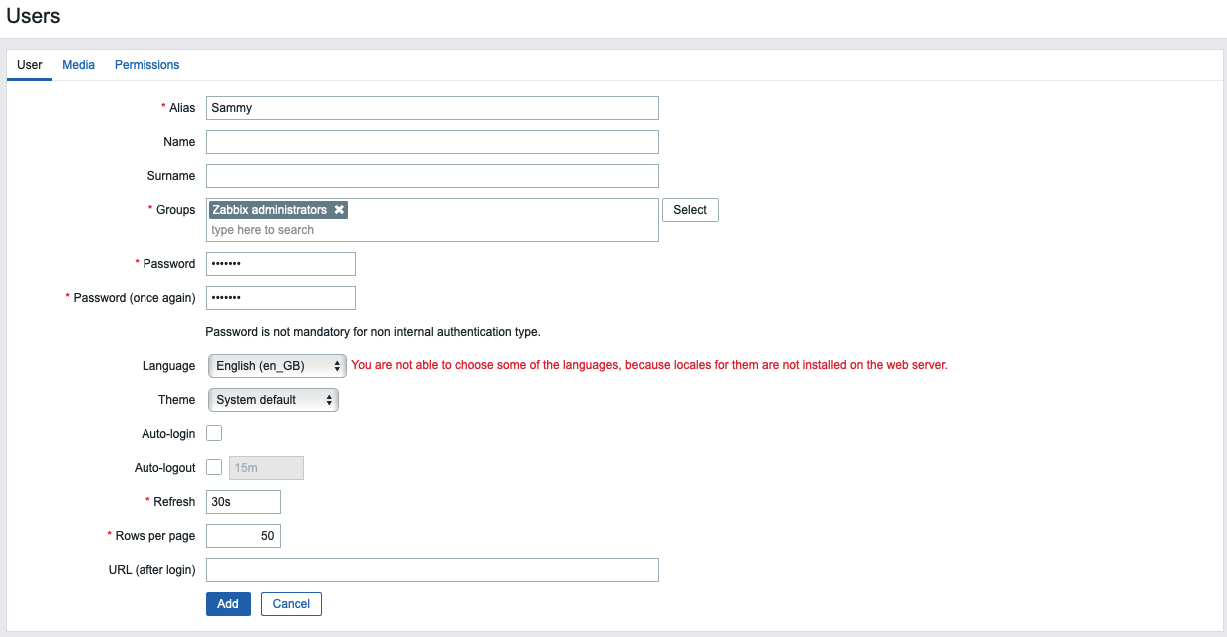
Enter the new username in the Alias field and set up a new password. Next, add the user to the administrator’s group. Type Zabbix administrators in the Groups field and select it from the proposed list.
Once you’ve added the group, click the Media tab and click on the Add underlined link (not the Add button below it). You will see a pop-up window.
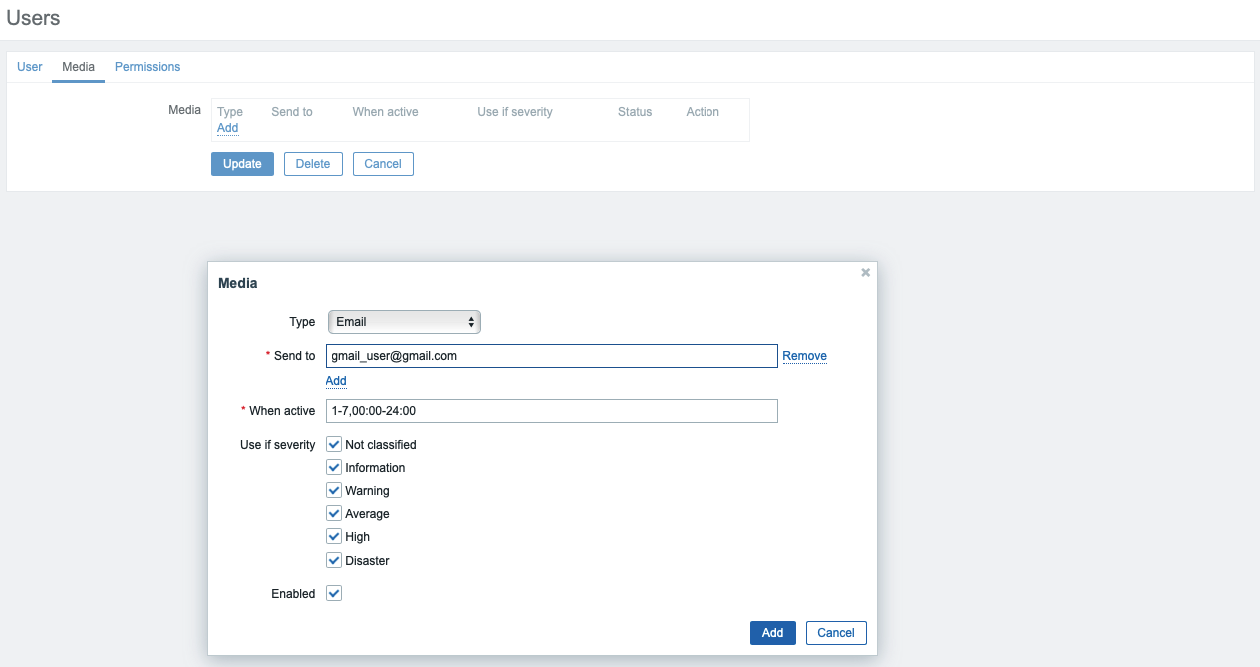
Select the Email option from the Type drop down. Enter your email address in the Send to field. You can leave the rest of the options at the default values. Click the Add button at the bottom to submit.
Now navigate to the Permissions tab. Select Zabbix Super Admin from the User type drop-down menu.
Finally, click the Add button at the bottom of the form to create the user.
Note: Using the default password is not safe. In order to change the password of the built-in user Admin click on the alias in the list of users. Then click Change password, enter a new password, and confirm the changes by clicking Update button.
Now you need to enable notifications. Click on the Configuration tab and then Actions in the left navigation bar. You will see a pre-configured action, which is responsible for sending notifications to all Zabbix administrators. You can review and change the settings by clicking on its name. For the purposes of this tutorial, use the default parameters. To enable the action, click on the red Disabled link in the Status column.
Now you are ready to receive alerts. In the next step, you will generate one to test your notification setup.
Step 9 — Generating a Test Alert
In this step, you will generate a test alert to ensure everything is connected. By default, Zabbix keeps track of the amount of free disk space on your server. It automatically detects all disk mounts and adds the corresponding checks. This discovery is executed every hour, so you need to wait a while for the notification to be triggered.
Create a temporary file that’s large enough to trigger Zabbix’s file system usage alert. To do this, log in to your second Ubuntu server if you’re not already connected:
- ssh sammy@second_ubuntu_server_ip_address
Next, determine how much free space you have on the server. You can use the df command to find out:
The command df will report the disk space usage of your file system, and the -h will make the output human-readable. You’ll see output like the following:
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 78G 1.4G 77G 2% /
In this case, the free space is 77G. Your free space may differ.
Use the fallocate command, which allows you to pre-allocate or de-allocate space to a file, to create a file that takes up more than 80% of the available disk space. This will be enough to trigger the alert:
- fallocate -l 70G /tmp/temp.img
After around an hour, Zabbix will trigger an alert about the amount of free disk space and will run the action you configured, sending the notification message. You can check your inbox for the message from the Zabbix server. You will see a message like:
Problem started at 09:49:08 on 2020.06.12
Problem name: /: Disk space is low (used > 80%)
Host: Second Ubuntu Server
Severity: Warning
Operational data: Space used: 71.34 GB of 77.36 GB (92.23 %)
Original problem ID: 106
You can also navigate to the Monitoring tab and then Dashboard to see the notification and its details.
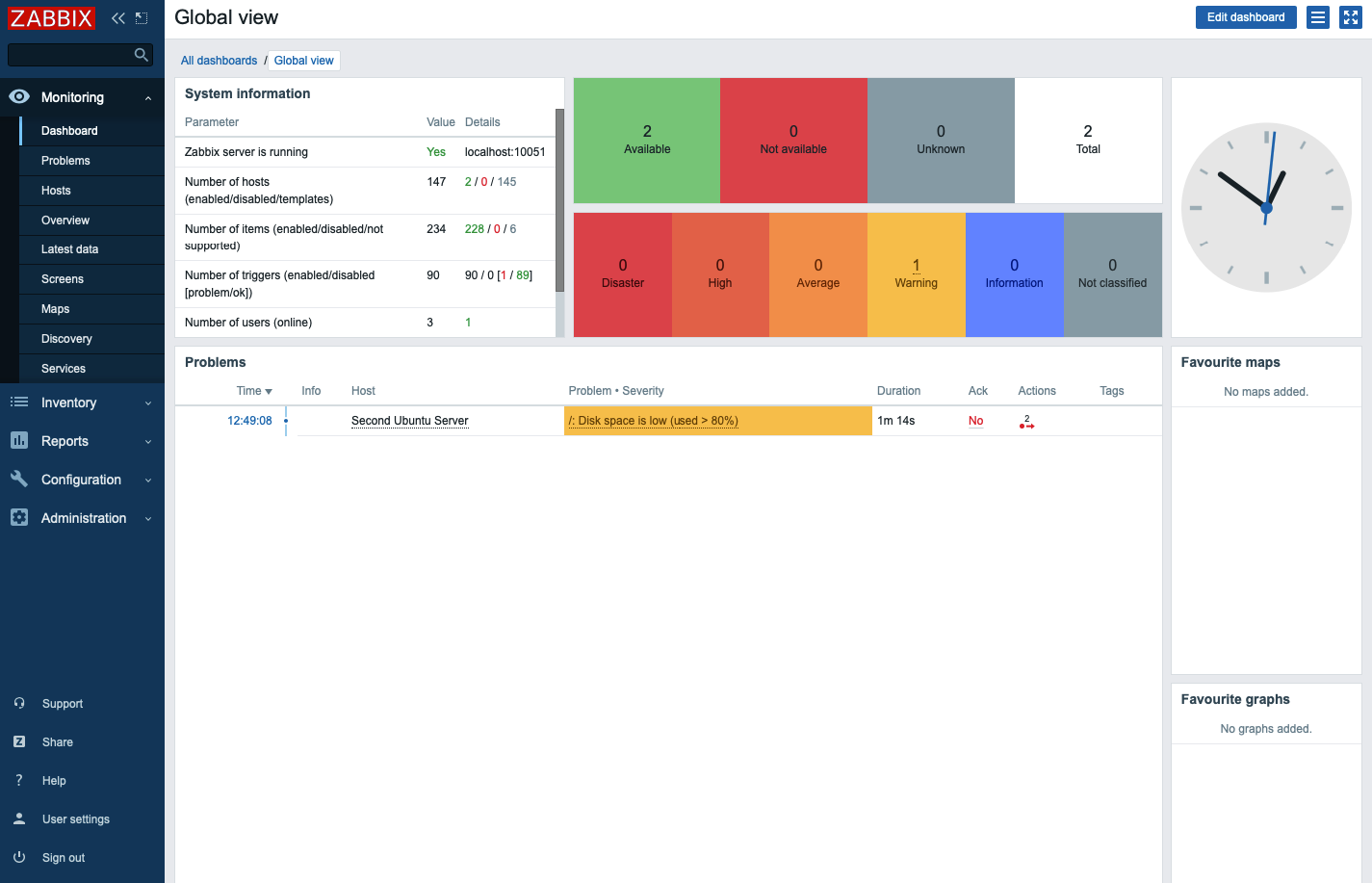
Now that you know the alerts are working, delete the temporary file you created so you can reclaim your disk space:
After a minute Zabbix will send the recovery message and the alert will disappear from the main dashboard.
Conclusion
In this tutorial, you learned how to set up a simple and secure monitoring solution that will help you monitor the state of your servers. It can now warn you of problems, and you have the opportunity to analyze the processes occurring in your IT infrastructure.
To learn more about setting up monitoring infrastructure, check out our Monitoring topic page.

![How To Install PostgreSQL on Ubuntu 20.04 [Quickstart]](https://wpcademy.com/wp-content/uploads/2020/11/PostgreSQL-on-Ubuntu-20.04-.jpg)