Introduction
Streaming replication is a popular method you can use to horizontally scale your relational databases. It uses two or more copies of the same database cluster running on separate machines. One database cluster is referred to as the primary and serves both read and write operations; the others, referred to as the replicas, serve only read operations. You can also use streaming replication to provide high availability of a system. If the primary database cluster or server were to unexpectedly fail, the replicas are able to continue serving read operations, or (one of the replicas) become the new primary cluster.
PostgreSQL is a widely used relational database that supports both logical and physical replication. Logical replication streams high-level changes from the primary database cluster to the replica databases. Using logical replication, you can stream changes to just a single database or table in a database. However, in physical replication, changes to the WAL (Write-Ahead-Logging) log file are streamed and replicated in the replica clusters. As a result, you can’t replicate specific areas of a primary database cluster, but instead all changes to the primary are replicated.
In this tutorial, you will set up physical streaming replication with PostgreSQL 12 on Ubuntu 20.04 using two separate machines running two separate PostgreSQL 12 clusters. One machine will be the primary and the other, the replica.
To complete this tutorial, you will need the following:
- Two separate machines Ubuntu 20.04 machines; one referred to as the primary and the other referred to as the replica. You can set these up with our Initial Server Setup Guide, including non-root users with sudo permissions and a firewall.
- Your firewalls configured to allow HTTP/HTTPS and traffic on port
5432—the default port used by PostgreSQL 12. You can follow How To Set Up a Firewall with ufw on Ubuntu 20.04 to configure these firewall settings. - PostgreSQL 12 running on both Ubuntu 20.04 Servers. Follow Step 1 of the How To Install and Use PostgreSQL on Ubuntu 20.04 tutorial that covers the installation and basic usage of PostgreSQL on Ubuntu 20.04.
Step 1 — Configuring the Primary Database to Accept Connections
In this first step, you’ll configure the primary database to allow your replica database(s) to connect. By default, PostgreSQL only listens to the localhost (127.0.0.1) for connections. To change this, you’ll first edit the listen_addresses configuration parameter on the primary database.
On your primary server, run the following command to connect to the PostgreSQL cluster as the default postgres user:
Once you have connected to the database, you’ll modify the listen_addresses parameter using the ALTER SYSTEM command:
Replace 'your_replica_IP_addr' with the IP address of your replica machine.
You will receive the following output:
ALTER SYSTEM
The command you just entered instructs the PostgreSQL database cluster to allow connections only from your replica machine. If you were using more than one replica machine, you would list the IP addresses of all your replicas separated by commas. You could also use '*' to allow connections from all IP addresses, however, this isn’t recommended for security reasons.
Note: You can also run the command on the database from the terminal using psql -c as follows:
Alternatively, you can change the value for listen_addresses by manually editing the postgresql.conf configuration file, which you can find in the /etc/postgresql/12/main/ directory by default. You can also get the location of the configuration file by running SHOW config_file; on the database cluster.
To open the file using nano use:
Once you’re done, your primary database will now accept connections from other machines. Next, you’ll create a role with the appropriate permissions that the replica will use when connecting to the primary.
Step 2 — Creating a Special Role with Replication Permissions
Now, you need to create a role in the primary database that has permission to replicate the database. Your replica will use this role when connecting to the primary. Creating a separate role just for replication also has security benefits. Your replica won’t be able to manipulate any data on the primary; it will only be able to replicate the data.
To create a role, you need to run the following command on the primary cluster:
You’ll receive the following output:
CREATE ROLE
This command creates a role named test with the password 'testpassword', which has permission to replicate the database cluster.
PostgreSQL has a special replication pseudo-database that the replica connects to, but you first need to edit the /etc/postgresql/12/main/pg_hba.conf configuration file to allow your replica to access it. So, exit the PostgreSQL command prompt by running:
Now that you’re back at your terminal command prompt, open the /etc/postgresql/12/main/pg_hba.conf configuration file using nano:
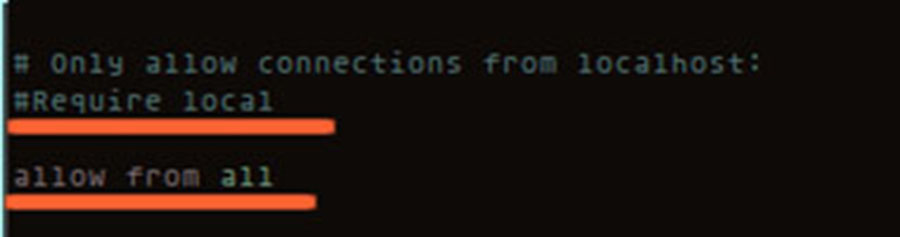
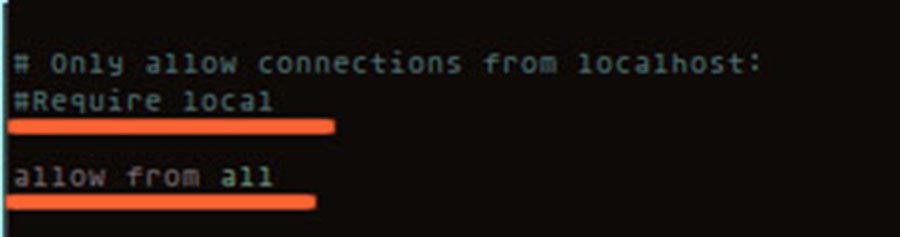
Append the following line to the end of the pg_hba.conf file:
This ensures that your primary allows your replica to connect to the replication pseudo-database using the role, test, you created earlier. The host value means to accept non-local connections via plain or SSL-encrypted TCP/IP sockets. replication is the name of the special pseudo-database that PostgreSQL uses for replication. Finally, the value md5 is the type of authentication used. If you want to have more than one replica, just add the same line again to the end of the file with the IP address of your other replica.
To ensure these changes to the configuration file are implemented, you need to restart the primary cluster using:
If your primary cluster restarted successfully, it is correctly set up and ready to start streaming once your replica connects. Next, you’ll move on to setting up your replica cluster.
Step 3 — Backing Up the Primary Cluster on the Replica
As you are setting up physical replication with PostgreSQL in this tutorial, you need to perform a physical backup of the primary cluster’s data files into the replica’s data directory. To do this, you’ll first clear out all the files in the replica’s data directory. The default data directory for PostgreSQL on Ubuntu is /var/lib/postgresql/12/main/.
You can also find PostgreSQL’s data directory by running the following command on the replica’s database:
Once you have the location of the data directory, run the following command to remove everything:
Since the default owner of the files in the directory is the postgres user, you will need to run the command as postgres using sudo -u postgres.
Note:
If in the exceedingly rare case a file in the directory is corrupted and the command does not work, remove the main directory all together and recreate it with the appropriate permissions as follows:
Now that the replica’s data directory is empty, you can perform a physical backup of the primary’s data files. PostgreSQL conveniently has the utility pg_basebackup that simplifies the process. It even allows you to put the server into standby mode using the -R option.
Execute the pg_basebackup command on the replica as follows:
- The
-hoption specifies a non-local host. Here, you need to enter the IP address of your server with the primary cluster. - The
-poption specifies the port number it connects to on the primary server. By default, PostgreSQL uses port:5432. - The
-Uoption allows you to specify the user you connect to the primary cluster as. This is the role you created in the previous step. - The
-Dflag is the output directory of the backup. This is your replica’s data directory that you emptied just before. - The
-Fpspecifies the data to be outputted in the plain format instead of as atarfile. -Xsstreams the contents of the WAL log as the backup of the primary is performed.- Lastly,
-Rcreates an empty file, namedstandby.signal, in the replica’s data directory. This file lets your replica cluster know that it should operate as a standby server. The-Roption also adds the connection information about the primary server to thepostgresql.auto.conffile. This is a special configuration file that is read whenever the regularpostgresql.conffile is read, but the values in the.autofile override the values in the regular configuration file.
When the pg_basebackup command connects to the primary, you will be prompted to enter the password for the role you created in the previous step. Depending on the size of your primary database cluster, it may take some time to copy all the files.
Your replica will now have all the data files from the primary that it requires to begin replication. Next, you’ll be putting the replica into standby mode and start replicating.
Step 4 — Restarting and Testing the Clusters
Now that the primary cluster’s data files have been successfully backed up on the replica, the next step is to restart the replica database cluster to put it into standby mode. To restart the replica database, run the following command:
If your replica cluster restarted in standby mode successfully, it should have already connected to the primary database cluster on your other machine. To check if the replica has connected to the primary and the primary is streaming, connect to the primary database cluster by running:
Now query the pg_stat_replication table on the primary database cluster as follows:
Running this query on the primary cluster will output something similar to the following:
client_addr | state
------------------+-----------
your_replica_IP | streaming
If you have similar output, then the primary is correctly streaming to the replica.
conclusion
You now have two Ubuntu 20.04 servers each with a PostgreSQL 12 database cluster running with physical streaming between them. Any changes now made to the primary database cluster will also appear in the replica cluster.
You can also add more replicas to your setup if your databases need to handle more traffic.
If you wish to learn more about physical streaming replication including how to set up synchronous replication to ensure zero chance of losing any mission-critical data, you can read the entry in the official PostgreSQL docs.
![How To Install PostgreSQL on Ubuntu 20.04 [Quickstart]](https://wpcademy.com/wp-content/uploads/2020/11/PostgreSQL-on-Ubuntu-20.04-.jpg)